
3 questions to know if Event Storming the Flow could help you
Event storming can be used to improve the flow of work. Answer 3 questions to know if the technique is your go-to choice to address your workflow challenges.
The story of a team that was performing
The Genesis team is working on a software product. The team was once famous for its capacity to respond to client requests extremely fast. Yet, during the last year, each time they received such a request, their work always ended up generating new issues: regressions on the existing code, workarounds that are more and more complex to find, more time dedicated to testing and fixing the regressions than to implement the actual solution.
Although Genesis team members still wished to answer client requests fast, it seemed that a mystery spell had been cast against them. This situation felt as stressful as being trapped in an ever-growing snowball running downhill with no idea on how to stop it. The more they wanted to bring back their capacity to respond to client requests quickly, the longer it would take them.
The story of a team that was anticipating market needs
The Moonraker team is working on another software product. Not long ago, Moonraker people were assigned a task to anticipate a future market need, based on strategic analysis from product people in the management.
Moonraker guys started developing a new component (let’s call it ‘error handling’, although we don’t really care about what it is for the purpose of this post). It took them 1,5 years to design, build, and test the first version. The good news is that it coincided with the moment when the first client use case was identified. The bad news was that the volume of ‘errors’ that the ‘error handling’ component should have handled for this client was way higher than what it was meant to be. As the client use case needed to be covered quickly, an architectural decision was made to have the client-facing team (another one) build a local workaround for this specific client. Although the client would be satisfied, it was a ‘cosmetic gesture’. The decision clearly acknowledged that some technical debt was created and would need to be repaid.
When a second client use case was identified, Moonraker people had started to work on other quite urgent stuff. Consequently, Moonraker could only dedicate time during the next 4 weeks to address this new request for the new use case. Although there were still some questions on the level of performance for error handling, the plan to dedicate a limited amount of time seemed acceptable, as the new request was documented with a design to implement. Moonraker people started to work right away. A commitment by the client manager was made to the new client.
We are now one week away to the delivery date. Moonraker people made assumptions with regards to the targeted performance level. They are under pressure to deliver on time, while still taking care of their other urgent stuff. They are raising the question. What is the plan B in case we are late or our assumptions are wrong?
Why are these stories similar?
These stories have three aspects in common
- The problems that they describe are not about a lack of skills
The skills, experience, and knowledge of the team members are unquestionable. The teams have all the necessary skills and experience to deliver the products they are working on.
- The problem persists
In both cases, the sensation of a snowball running downhill is present. For Genesis, no matter what they do, it keeps taking them longer to answer client requests. For Moonraker, no matter what they do, they have difficulties to build a solution that corresponds to the needs. There is a risk for them to lose the trust of their stakeholders.
- There is no obvious solution
When reading these stories, you probably identified a few possible dysfunctions. For example, Genesis probably did not take care of their accumulating technical debt early and continuously enough. Or they may do testing too late in their workflow. Moonraker started their new work assignment with no real client use case, which is probably a recipe for failure.
These hypothetical dysfunctions are probably real. Having said that, you can not be sure that these are the only dysfunctions or even the main ones. Besides, you can hardly know what may have caused these dysfunctions in the first place. And even if you could determine a clear set of causes, it is more valuable to identify what to do to change these dysfunctions than to identify their causes.
What would an event storming the flow workshop bring?
When you do an event storming of the flow, you will visualize the events that occur during the flow of the work you are examining.

Then you will look for patterns and feedback loops.
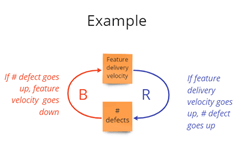
From there, you will identify levers where to act.
This will allow you to you to identify actions. These actions aim at changing the system that creates the repetitive patterns resulting in the events. Starting with visualization and doing the next steps allow you dig into the system and to not stay on the ‘apparent problems and solutions’ that only contribute to perpetuate the snowball effect.
How to know if Event Storming the Flow could help you?
In a nutshell, whether your team is working on a software or not, the typical situations in which event storming the flow makes sense are the ones where your answers to the 3 following questions would be no, yes and no:
- Is it a problem of skills? no
- Has the problem been persisting or even growing despite the effort you or your team already put into solving it? yes
- Is there one obvious solution? no
If your answers correspond, stay tuned. In the next post, 5 ingredients to prepare before starting an event storming the flow , you will learn more about Event Storming the flow and get ready to run this workshop on your own!
This blog post is part of the 1h Event Storming book that we are currently writing.



Leave a comment